– This post is a compilation of four old posts. They are gathered here in one piece for more clarity, and for archiving purpose. The work described in this post was done over the years 2014-2016 –
Riak as Events Storage
Booking.com constantly monitors, inspects, and
analyzes our systems in order to make decisions. We capture and channel
events from our various subsystems, then perform real-time, medium
and long-term computation and analysis.
This is a critical operational process, since our daily work always gives
precedence to data. Relying on data removes the guesswork in making sound
decisions.
In this series of blog posts, we will outline details of our data pipeline, and
take a closer look at the short and medium-term storage layer that was
implemented using Riak.
Introduction to Events Storage
Booking.com receives, creates, and sends an enormous amount of data. Usual
business-related data is handled by traditional databases, caching systems,
etc. We define events as data that is generated by all the subsystems on
Booking.com.
In essence, events are free-form documents that contain a variety of metrics.
The generated data does not contain any direct operational information.
Instead, it is used to report status, states, secondary information, logs,
messages, errors and warnings, health, and so on. The data flow represents a
detailed status of the platform and contains crucial information that will be
harvested and used further down the stream.
To put this in numerical terms - we have more than billions of events per
day, streaming at more than 100 MB per second, and adding up to more than
6 TB per day.
Here are some examples of how we use the events stream:
- Visualisation: Wherever possible, we use graphs to express data. To create them, we use a heavily-modified version of Graphite.
- Looking for anomalies: When something goes wrong, we need to be notified. We use threshold-based notification systems (like seyren) as well as a custom anomaly detection software, which creates statistical metrics (e.g. change in standard deviation) and alerts if those metrics look suspicious.
- Gathering errors: We use our data pipeline to pass stack traces from all our production servers into ElasticSearch. Doing it this way (as opposed to straight from the web application log files) allows us to correlate errors with the wealth of the information we store in the events.
These typical use-cases are made available in less than one-minute after the related event has been generated.
High Level overview
This is a very simplified diagram of the data flow:
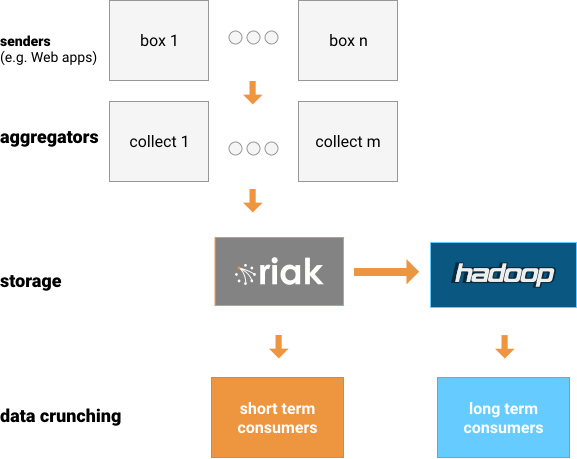
We can generate events by using literally any piece of code that exists on our
servers. We pass a HashMap to a function, which packages the provided document
into a UDP packet and sends it to a collection layer. This layer aggregates all
the events together into “blobs”, which are split by seconds (also called
epochs) and other variables. These event blobs are then sent to the storage
layer running Riak. Finally, Riak sends them on to
Hadoop. The Riak cluster is meant to safely store
around ten days of data. It is used for near real-time analysis (something
that happened seconds or minutes ago), and medium-term analysis of
relatively small amounts of data. We use Hadoop for older data analysis or
analysis of a larger volume of data.
The above diagram is a simplified version of our data flow. In practical application, it’s spread across multiple datacenters (DC), and includes an additional aggregation layer.
Individual Events
An event is a small schema-less [1] piece of data sent by our systems.
That means that the data can be in any structure with any level of depth, as
long as the top level is a HashTable. This is crucial to Booking.com - the goal
is to give as much flexibility as possible for the sender, so that it’s easy to
add or modify the structure, or the type and number of events.
Events are also tagged in four different ways:
- the epoch at which they were created
- the DC where they originated
- the type of event
- the subtype.
Some common types are:
- WEB events (events produced by code running under a web server)
- CRON events (output of cron jobs)
- LB events (load balancer events)
The subtypes are there for further specification and can answer questions like:
“Which one of web server systems are we talking about?”.
Events are compressed Sereal
blobs. Sereal is possibly the
best schema-less serialisation format
currently available. It was also
written at Booking.com.
An individual event is not very big, but a huge number of them are sent every
second.
We use UDP as transport because it provides a fast and simple way to send data.
Despite some (very low) risk of data loss, it doesn’t impact senders sending
events. We are experimenting with an UDP-to-TCP relay that will be local to the
senders.
Aggregated Events
Literally every second, events from this particular second (called epoch), DC
number, type, and subtype are merged together as an Array of events on the
aggregation layer. At this point, it’s important to try and get the smallest
size possible, so the events of a given epoch are re-serialized as a Sereal
blob, using these options:
compress => Sereal::Encoder::SRL_ZLIB,
dedupe_strings => 1
dedupe_strings increases the serialisation time slightly. However it removes
strings duplications which occur a lot since events are usually quite similar
between them. We also add gzip compression.
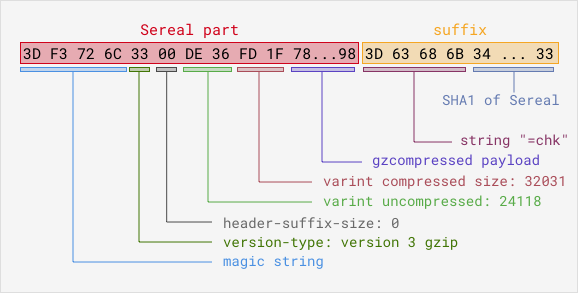
We also add the checksum of the blob as a postfix, to be able to ensure data
integrity later on. The following diagram shows what an aggregated blob of
events looks like for a given epoch, DC, type, and subtype. You can get more
information about the Sereal encoding in the
Sereal Specification.
This is the general structure of an events blob:
The compressed payload contains the events themselves. It’s an Array of HashMaps,
Serialized in a Sereal structure and gzip-compressed. Here is an example of a
trivial payload of two events, as follows:
[
{ cpu => 5 },
{ cpu => 99 }
]
And the gzipped payload would be the compressed version of this binary string:
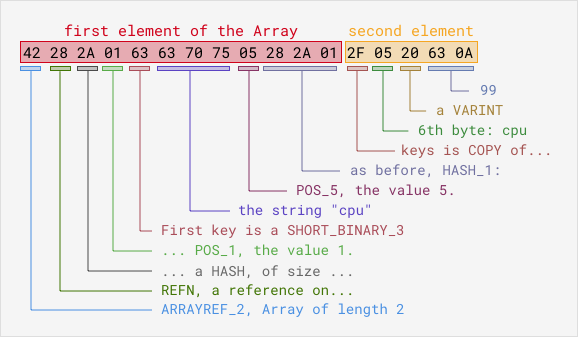
It can be hard to follow these hexdigits [2], yet it’s a nice illustration
of why the Sereal format helps us to reduce the size of serialised data. The
second array element is encoded on far fewer bytes than the first one, since
the key has already be seen. The resulting binary is then re-compressed. The
Sereal implementation offers multiple compression algorithms, including
Snappy and gzip.
A typical blob of events for one second/DC/type/subtype can weight anywhere from
several kilobytes to several megabytes, which translates into a (current) average
of around 250 gigabytes per hour.
Side note: smaller subtypes on this level of aggregation aren’t always used,
because we want to minimise the data we transmit over our network by having good
compression ratios. Therefore we split types into subtypes only when the blobs
are big enough. The downside to this approach is that consumers have to fetch
data for the whole type, then filter out only subtypes they want. We’re looking
at ways to find more balance here.
Data flow size and properties
Data flow properties are important, since they’re used to decide how data
should be stored:
- The data is timed and all the events blobs are associated with an epoch. It’s
important to bear in mind that events are schema-less, so the data is not a
traditional time series.
- Data can be considered read-only; the aggregated events blobs are written every second and almost never modified
(history rewriting happens very rarely).
- Once sent to the storage, the data must be available as soon as possible
Data is used in different ways on the client side. A lot of consumers are
actually daemons that will consume the fresh data as soon as possible - usually
seconds after an event was emitted. A large number of clients read the last few
hours of data in a chronological sequence. On rare occasions, consumers access
random data that is over a few days old. Finally, consumers that want to work on larger
amounts of older data would have to create Hadoop jobs.
There is a large volume of data to be moved and stored. In numerical terms:
- Once serialized and compressed into blobs, it is usually larger than 50 MB/s
- That’s around 250 GB per hour and more than 6 TB per day
- There is a daily peak hour but the variance of the data size is not huge:
There are no quiet periods
- Yearly peak season stresses all our systems, including events
transportation and storage, so we need to provision capacity for that
Why Riak
In order to find the best storage solution for our needs, we tested and
benchmarked several different products and solutions.
The solutions had to reach the right balance of multiple features:
- Read performance had to be high as a lot of external processes will use the data.
- Write security was important, as we had to ensure that the continuous flow of
data could be stored. Write performance should not be impacted by reads.
- Horizontal scalability was of utmost importance, as our business and traffic continuously grows.
- Data resilience was key: we didn’t want to lose portions of our data because of a hardware problem.
- Allowed a small team to administrate and make the storage evolve.
- The storage shouldn’t require the data to have a specific schema or
structure.
- If possible, it would be able to bring code to data, perform computation on the
storage itself, instead of having to get data out of the storage.
After exploring a number of distributed file systems and databases, we chose
Riak over distributed Key-Value stores. Riak had good performance and
predictable behavior when nodes fail and when scaling up. It also had the
advantage of being easy to grasp and implement within a small team. Extending
it was very easy (which we’ll see in the next part of this series of blog
posts) and we found the system very robust - we never had to face dramatic
issues or data loss.
Disclaimer: This is not an endorsment for Riak. We compared it carefully to
other solutions over a long period of time and it seemed to be the best product
to suit our needs. As an example, we thoroughly tested Cassandra as an
alternative: it had a larger community and similar performance but was less
robust and predictable; it also lacked some advanced features. The choice is
ultimately a question of priorities. The fact that our events are
schema-less made it almost impossible for us to use solutions that require
knowledge of the data structures. Also we needed a small team to be able to
operate the storage, and a way to process data on the cluster itself, using
MapReduce or similar mechanisms.
Riak 101
The Riak cluster is a collection of nodes (in our case physical servers), each
of which claims ownership of a given key. Depending on the chosen replication
factor, each key might be owned by multiple nodes. You can ask any node for
a key and your request will be redirected to one of the owners. Same goes for
writes.
On closer inspection of Riak, we see that keys are grouped into virtual nodes.
Each physical node can own multiple virtual nodes. This simplifies data
rebalancing when growing a cluster. Riak does not need to recalculate the owner
for each individual key; it will only do it per virtual node.
We won’t cover Riak architecture in a great detail in this post, but we
recommend reading the
following article
for further information.
Riak clusters configuration
The primary goal of this storage is to keep the data safe. We went with the
regular replication number value of three. Even if two nodes owning the same
data will go down, we won’t lose our data.
Riak offers multiple back-ends for actual data storage. The main three are
Memory, LevelDB, and Bitcask. We chose Bitcask, since it was suitable for our
particular needs. Bitcask uses log-structured hash tables that provide very
fast access. As data gets written to the storage, Bitcask simply appends data
to a number of opened files. Even if a key is modified or deleted, the
information will be written at the end of these storage files. An in-memory
HashTable maps the keys with the position of their (latest) value in files.
That way, at most one seek is needed to fetch data from the file system.
Data files are then periodically compacted, and Bitcask provides very good
expiration flexibility. Since Riak is a temporary storage solution for us, we
set it up with automatic expiration. Our expiration period varies. It depends
on the current cluster shape, but usually falls between 8-11 days.
Bitcask keeps all of the keys of a node in memory, so keeping large numbers of
individual events as key value pairs isn’t trivial. We sidestep any issues by
using aggregations of events (blobs), which drastically reduce the number of
needed keys.
More information about Bitcask can be found here.
For our conflict resolution strategy, we use Last Write Wins. The nature of our
data (which is immutable as we described before) allows us to avoid the need
for conflict resolution.
The last important part of our setup is load balancing. It is crucial in an
enviromnent with a high level of reads, and only 1 gigabyte network. We use our
own solution for that based on Zookeeper.
Zooanimal daemons are running on the riak nodes, and collect information about
system health. The information is then aggregated into simple text files, where
we have an ordered list of IP addresses, plus up and running Riak nodes, which
we can connect to. All our Riak clients simply choose a random node to send
their requests to.
We currently have two Riak clusters in different geographical locations, each
of which have more than 30 nodes. More nodes equates to more storage space, CPU
power, RAM, and more network bandwidth available.
Data Design
Riak is primarily a key-value store. Although it provides advanced features
(secondary indexes, MapReduce, CRDTs), the simplest and most efficient way to
store and retrieve data is to use the key-value model.
Riak has three concepts - a bucket is a namespace, in which a key is
unique. A key is the identifier of the data; and has to be stored in a
bucket. A value is the data; it has an associated mime-type, which can
enable Riak awareness of its type.
Riak doesn’t provide efficient ways to retrieve the list of buckets or the list
of keys by default [3]. When using Riak, it’s important to know the bucket
and key to access. This is usually resolved by using self-explanatory
identifiers.
In our case, our events are stored as Sereal-encoded blobs. From these, we know
the datacenter, type, subtype, and of course the time at which it was created.
When we need to retrieve data, we always know the time we want. We are also
confident in the list of our datacenters. It doesn’t change unexpectedly so we
can make it static for our applications. We are not always sure about what
types or subtypes will appear in a given epoch for a given datacenter. On some
seconds events of certain types may not arrive.
We came up with this simple data design:
- events blobs are stored in the events bucket, keys being
<epoch>:<dc>:<type>:<subtype>:<chunk>
- metadata are stored in the epochs bucket, keys being
<epoch>:<dc> and
values being the list of events keys for this epoch and DC combination
The value of chunk is an integer, starting at zero, which keeps event blobs
smaller than 500 kilobytes each. We use the integer to split big events blobs
into smaller ones, so that Riak can function more efficiently.
We’ll now see this data design in action when pushing data to Riak
Pushing to Riak
Pushing data to Riak is done by a number of relocators, which are daemons
running on the aggregation layer that then push events blobs to Riak.
Side note: it’s not recommended to have keys more then 1-2MB in Riak (see this FAQ).
And since our blobs can be 5-10MB in size, we shard them into chunks, 500KB each.
Chunks are valid Sereal documents, which means we do not have to stich chunks together in order to retrieve data back.
This means that we have quite a lot of blobs to send to Riak, so to maximise our usage of
networking, I/O, and CPU, it’s best to send data in a mass-parallel way. To do so, we maintain a number of
forked processes (20 per host is a good start), in which each of them push data to Riak.
Pushing data to Riak can be done using the
HTTP API, or the
Protocol Buffers Client (PBC) API.
PBC has a slighly better performance.
Whatever protocol is used, it’s important to maximise I/O utilisation. One way
is to use an HTTP library that parallelises the requests in term of I/O
(YAHC is an example). Another method is to use
an asynchronous Riak Client like
AnyEvent::Riak.
We use an in-house library to create and maintain a pool of forks, but there are more than one existing libraries on CPAN, like
Parallel::ForkManager.
PUT to Riak
Writing data to Riak is rather simple. For a given epoch, we have the list of
events blobs, each of them having a different DC/type/subtype combination (remember, DC is short for Data Center). For example:
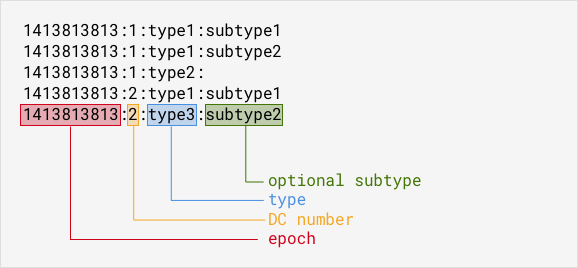
The first task is to slice the blobs into 500 KB chunks and add a postfix index
number to their name. That gives:
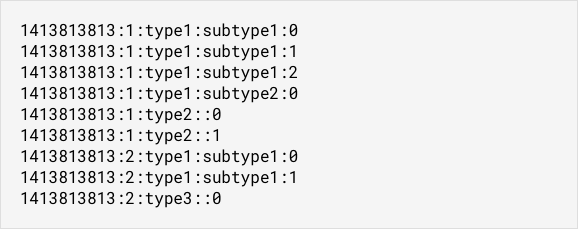
Next, we can store all the event blobs in Riak in the events bucket. We can
simulate it with curl:
curl -d <data> -XPUT "http://node:8098/buckets/events/keys/1413813813:1:type1:subtype1:0"
# ...
curl -d <data> -XPUT "http://node:8098/buckets/events/keys/1413813813:2:type3::0"
Side note: we store all events in each of the available Riak clusters. In other
words, all events from all DCs will be stored in the Riak cluster which is in DC
1, as well as in the Riak cluster which is in DC 2. We do not use cross DC
replication to achieve that - instead we simply push data to all our clusters
from the relocators.
Once all the events blobs are stored, we can store the metadata, which is
the list of the event keys, in the epochs bucket. This metadata is stored in one
key per epoch and DC. So for the current example, we will have 2 keys:
1413813813-1 and 1413813813-2. We have chosen to store the list of events
blobs names as pipe separated values. Here is a simulation with curl for
DC 2:
curl -d "type1:subtype1:0|type1:subtype1:1|type3::0" -XPUT "http://riak_host:8098/buckets/epochs/keys/1413813813-2"
Because the epoch and DC are already in the key name, it’s not necessary to
repeat that in the content. It’s important to push the metadata after
pushing the data.
PUT options
When pushing data to the Riak cluster, we can use different attributes to
change the way data is written - either by specifying which ones when using the PBC
API, or by setting the buckets defaults.
Riak’s documentation provides a comprehensive list of the parameters and their meaning. We have set these parameters as follows:
"n_val" : 3,
"allow_mult" : false,
"last_write_wins" : true,
"w" : 3,
"dw" : 0,
"pw" : 0,
Here is a brief explanation of these parameters:
n_val:3 means that the data is replicated three timesallow_mult and last_write_wins prohibit siblings values; conflicts are resolved right away by using the last value
writtenw:3 means that when writing data to a node, we get a success response only when the data has been written to all the three
replica nodesdw:0 instruct Riak to wait for the data to have reached the node, not the backend on the node, before returning success.pw:0 is here to specify that it’s OK if the nodes that store the replicas are not the primary nodes (i.e. the ones that are supposed to hold the data), but replacement nodes, in case the primary ones were unavailable.
In a nutshell, we have a reasonably robust way of writing data. Because our
data is immutable and never modified, we don’t want to have siblings or
conflict resolution on the application level. Data loss could, in theory, happen
if a major network issue happened just after having acknowledged a write, but
before the data reached the backend. However, in the worst case we would lose a
fraction of one second of events, which is acceptable for us.
Reading from Riak
This is how the data and metadata for a given epoch is laid out in Riak:
bucket: epochs
key: 1428415043-1
value: 1:cell0:WEB:app:chunk0|1:cell0:EMK::chunk0
bucket: events
key: 1428415043:1:cell0:WEB:app:chunk0
value: <binary sereal blob>
bucket: events
key: 1428415043:1:cell0:EMK::chunk0
value: <binary sereal blob>
Fetching one second of data from Riak is quite simple. Given a DC and an epoch,
the process is as follow:
- Read the metadata by fetching the key
<epoch>-<dc> from the bucket "epochs"
- Parse the metadata value, split on the pipe character to get data keys, and prepend the epoch to them
- Reject data keys that we are not interested in by filtering on type/subtype
- Fetch the data keys in parallel
- Deserialise the data
- Data is now ready for processing
Reading a time range of data is done the same way. Fetching ten minutes of
data from Wed, 01 Jul 2015 11:00:00 GMT would be done by enumerating all the
epochs, in this case:
1435748400
1435748401
1435748402
...
1435749000
Then, for each epoch, fetch the data as previously mentioned. It should be noted
that Riak is specifically tailored for this kind of workload, where multiple
parallel processes perform a huge number of small requests on different keys.
This is where distributed systems shine.
GET options
The events bucket (where the event data is stored) has the following properties:
"r" : 1,
"pr" : 0,
"rw" : "quorum",
"basic_quorum" : true,
"notfound_ok" : true,
Again, let’s look at these parameters in detail:
r:1 means that when fetching data, as soon as we have a reply from one replica
node, Riak considers this as a valid reply, it won’t to compare it with
other replicas.pr:0 remove the requirement that the data comes from a primary nodenotfound_ok:true makes it so that as soon as one node can’t find a key, Riak considers that the
key doesn’t exist (notfound_ok:true).
These parameter values allow to be as fast as possible when fetching data. In
theory, such values don’t protect against conflicts or data corruption.
However, in the “Aggregated Events” section (see the first post), we’ve seen that every event blob
has a suffix checksum. When fetching them from Riak, this enables the consumer
to verify that there is no data corruption. The fact that the events are never
modified ensures that no version conflict can occur. This is why having such
“careless” parameter values is not an issue for this use case.
Real time data processing outside of Riak
After the events are properly stored in Riak, it’s time to use them. The first
usage is quite simple: extract data out of them and process it on dedicated
machines, usually grouped in clusters or aggregations of machines that perform
the same kind of analysis. These machines are called consumers, and they
usually run daemons that fetch data from Riak, either continuously or on
demand. Most of the continuous consumers are actually small clusters of machines
spreading the load of fetching data.
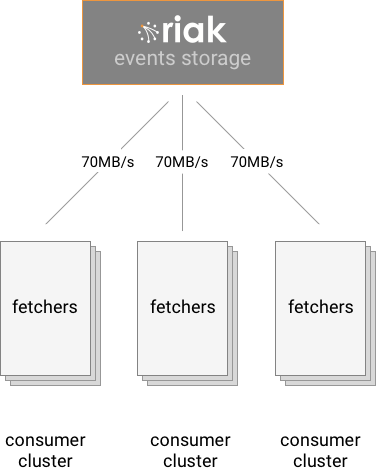
Some data processing is required at near real-time. This is the case for
monitoring, and building graphs. Booking.com heavily uses graphs at every
layer of its technical stack. A big portion of graphs are generated from
Events. Data is fetched every second from the Riak storage, processed, and
dedicated graphing data is sent to an in-house Graphite cluster.
Other forms of monitoring also consume the events stream- fetched continuously
and aggregated in per-second, per-minute, and daily aggregations in external
databases, which are then provided to multiple departments via internal tools.
These kind of processes try to be as close as possible to real-time.
Currently there are 10 to 15 seconds of lag. This lag could be shorter: a
portion of it is due to the collection part of the pipeline, and an even bigger
part of it is due to the re-serialisation of the events as they are grouped
together, to reduce their size. A good deal of optimisation could be done there
to reduce the lag down to a couple of seconds [4]. However, there was no operational
requirement for reducing it and 15 seconds is small enough for our current
needs.
Another way of using the data is to stick to real-time, but accumulate seconds
in periods. One example is our Anomaly Detector, which continuously fetches
events from the Riak clusters. However, instead of using the data right away,
it accumulates it on short moving windows of time (every few minutes) and applies
statistical algorithms on it. The goal is to detect anomalous patterns in our
data stream and provide the first alert that prompts further action. Needless to
say, this client is critical.
Another similar usage is done when gathering data related to A/B testing. A large
number of machines harvest data from the events’ flow before processing it and storing
the results in dedicated databases for use in experimentation-related tooling.
There are a number of other usages of the data outside of Riak, including
manually looking at events to check new features behaviours or analysing past
issues / outages.
Limitations of data processing outside of Riak
Fetching data outside of the Riak clusters raises some issues that are
difficult to work around without changing the processing mechanism.
First of all, there is a clear network bandwidth limitation to the design: the
more consumer clusters there are, the more network bandwidth is used. Even with
large clusters (more than 30 nodes), it’s relatively easy to exhaust the
network capacity of all the nodes as more and more fetchers try to get data
from them.
Secondly, each consumer cluster tends to use only a small part of the events
flow. Even though consumers can filter out types, subtypes, and DCs, the
resulting events blobs still contain a large quantity of data that is
useless to the consumer. For storage efficiency, events need to be stored as
large compressed serialised blobs, so splitting them more by allowing more
subtyping is not possible [5].
Additionally, statically splitting the events content is too rigid since use of
the data changes over time and we do not want to be a bottleneck to change for
our downstream consumers. Part of an event from a given type that was critical
2 years ago might be used for minor monitoring now. A subtype that was heavily
used for six month may now be rarely used because of a technical change in the
producers.
Finally, the amount of CPU time needed to uncompress, load, and filter the
big events blobs is not tiny. It usually takes around five seconds to fetch,
uncompress, and filter one second’s worth of events. Which means that any
real-time data crunching requires multiple threads and likely multiple hosts -
usually a small cluster. It would be much simpler if Riak could provide a
real-time stream of data exactly tailored to the consumer need.
Next: data filtering and processing inside Riak
What if we could remove the CPU limitations by doing processing on the Riak
cluster itself? What if we could work around the network bandwidth issue
by generating sub-streams on the fly and in real-time on the Riak cluster?
This is exactly what we implemented, using simple concepts, and leveraging the
ease of use and hackability of Riak. These concepts and implementations will
be described in the next sections
Real-time server-side data processing: the theory
The reasoning is actually very simple. The final goal is to perform data
processing of the events blobs that are stored in Riak in real-time. Data
processing usually produces a very small result, and it appears to be a waste
of network bandwidth to fetch data outside of Riak to perform data analysis on consumer clusters, as in this example::
This diagram is equivalent to:

So instead of bringing the data to the processing code, let’s bring the code to
the data:

This is a typical use case for MapReduce. We’re going to see how to use
MapReduce on our dataset in Riak, and also why it’s not a usable solution.
For the rest of this post, it’s important to establish a reference for all the events that are stored for a time period of exactly one second. Because we already happen to store our events by a second (and call it an “epoch”), using this unit of measure is a practical consideration that we’ll refer to as epoch-data.
A first attempt: MapReduce
MapReduce is a very well known (if somewhat outdated) way of bringing the code near the data and distributing data processing. There are excellent papers explaining this approach for further background study.
Riak has a very good MapReduce implementation. MapReduce jobs can be written in
Javascript or Erlang. We highly recommend using Erlang for better performance.
To perform events processing of an epoch-data on Riak, the MapReduce job would
look like the following list. Metadata and data keys concepts are explained in
the part 2 of the blog series. Here are the MapReduce phases:
- Given a list of epochs and DCs, the input is the list of metadata keys,
and as additional parameter, the processing code to apply to the data.
- A first Map phase reads the metadata values and returns a list of data keys.
- A second Map phase reads the data values, deserialises it, applies the
processing code and returns the list of results.
- A Reduce phase aggregates the results together

This works just fine. For one epoch-data, one data processing code is properly
mapped to the events, the data deserialised and processed in around 0.1 second
(on our initial 12 nodes cluster). This is by itself an important result: it’s
taking less than one second to fully process one second worth of events. Riak
makes it possible to implement a real-time MapReduce processing system [6].
Should we just use MapReduce and be done with it? Not really, because our
use case involves multiple consumers doing different data processing at the
same time. Let’s see why this is an issue.
The metrics
To be able to test the MapReduce solution, we need a use case and some metrics
to measure.
The use case is the following: every second, multiple consumers (say 20) need
the result of one of the data processing (say 10) of the previous second.
We’ll consider that an epoch-data is roughly 70MB, data processing results
are around 10KB each. Also, we’ll consider that the Riak cluster is a 30
nodes ring with 10 real CPUs available for data processing on each node.
The first metric we can measure is the external network bandwidth usage. This is
the first factor that encouraged us to move away from fetching the events out
of Riak to do external processing. External bandwidth usage is the bandwidth
used to transfer data between the cluster as a whole, and the outside world.
The second metric is the internal network bandwidth usage. This represents
the network used between the nodes, inside of the Riak cluster.
Another metric is the time (more precisely the CPU-time) it takes to
deserialise the data. Because of the heavily compressed nature of our data,
decompression and deserialising one epoch-data takes roughly 5 sec.
The fourth metric is the CPU-time it take to process the deserialized data,
analyze it and produce a result. This is very fast (compared to
deserialisation), let’s assume 0.01 sec. at most.
Note: we are not taking into account the impact of storing the data in the
cluster (remember that events blobs are being stored every second) because it’s impacting the system the same way in both external processing and MapReduce.
Metrics when doing external processing
When doing standard data processing as seen in the previous part of this blog
series, one epoch-data is fetched out from Riak, and deserialised and
processed outside of Riak.
External bandwidth usage
The external bandwidth usage is high. For each query, the epoch-data is
transferred, so that’s 20 queries times 70MB/s = 1400 MB/s. Of course, this
number is properly spread across all the nodes, but that’s still roughly 1400
/ 30 = 47 MB/s. That, however, is just for the data processing. There is a small
overhead that comes from the clusterised nature of the system and from gossiping,
so let’s round that number to 50 MB/s per node, in external output network
bandwidth usage.
Internal bandwidth usage
The internal bandwidth usage is very high. Each time a key value is requested,
Riak will check its 3 replicas, and return the value. So 3 x 20 x 70MB/s = 4200
MB/s. Per node, it’s 4200 MB/s / 30 = 140 MB/s
Deserialise time
Deserialise time is zero: the data is deserialised outside of Riak.
Processing time
Processing time is zero: the data is processed outside of Riak.
Metrics when using MapReduce
When using MapReduce, the data processing code is sent to Riak, included in an
ad hoc MapReduce job, and executed on the Riak cluster by sending the orders
to the nodes where the epoch-data related data chunks are stored.
External bandwidth usage
When using MapReduce to perform data processing jobs, there is certainly a huge
gain in network bandwidth usage. For each query, only the results are
transferred, so 20 x 10KB/s = 200 KB/s.
Internal bandwidth usage
The internal usage is also very low: it’s only used to spread the MapReduce
jobs, transfer the results, and do bookkeeping. It’s hard to put a proper number
on it because of the way jobs and data are spread on the cluster, but overall
it’s using a couple of MB/s at most.
Deserialise time
Deserialise time is high: for each query, the data is deserialised, so 20 x 5 =
100 sec for the whole cluster. Each node has 10 CPUs available for
deserialisation, so the time needed to deserialise one second worth of data is
100/300 = 0.33 sec. We can easily see that this is an issue, because already
one third of all our CPU power is used for deserialising the same data in each
MapReduce instance. It’s a big waste of CPU time.
Processing time
Processing time is 20 x 0.01 = 0.2s for the whole cluster. This is really low
compared to the deserialise time.
Limitations of MapReduce
As we’ve seen, using MapReduce has its advantages: it’s a well-known standard,
and allows us to create real-time processing jobs. However it doesn’t scale:
because MapReduce jobs are isolated, they can’t share the deserialised data,
and CPU time is wasted, so it’s not possible to have more than one or two
dozens of real-time data processing jobs at the same time.
It’s possible to overcome this difficulty by caching the deserialised data in
memory, within the Erlang VM, on each node. CPU time would still be 3 times
higher than needed (because a map job can run on any of the 3 replicas that
contains the targeted data) but at least it wouldn’t be tied to the number of
parallel jobs.
Another issue is the fact that writing MapReduce jobs is not that easy,
especially because — in this case — it’s a prerequisite to know Erlang.
Last but not least, it’s possible to create very heavy MapReduce jobs, easily
consuming all the CPU time. This directly impacts the performance and
reliability of the cluster, and in extreme cases the cluster may be unable to
store incoming events at a sufficient pace. It’s not trivial to fully protect
the cluster against MapReduce misuse.
A better solution: post-commit hooks
To work around these limitations, We explored a different approach to enable real-time data processing on the
cluster that scales properly by deserialising data only once, allows us to cap
its CPU usage, and allows us to write the processing jobs in any language, while
still bringing the code to the data, removing most of the internal and external
network usage.
This technical solution is what is currently in production at
Booking.com on our Riak events storage clusters, and
it uses post-commit hooks and a companion service on the cluster nodes.
Strategy and Features##
The previous parts introduced the need for data processing of the events blobs
that are stored in Riak in real-time, and the strategy of bringing the code to the data:
Using MapReduce for computing on-demand data processing worked fine but didn’t
scale to many users (see part 3).
Finding an alternative to MapReduce for server-side real-time data processing
requires listing the required features of the system and the compromises that
can be made:
As seen in the previous parts of this blog series, we need to be able to
perform transformation on the incoming events, with as little delay as
possible. We don’t want any lag induced by a large batch processing. Luckily,
these transformations are usually small and fast. Moreover, they are
isolated: the real-time processing may involve multiple types and subtypes of
events data, but should not depend on previous events knowledge. Cross-epoch
data processing can be implemented by reusing the MapReduce concept, computing
a Map-like transformation on each events blobs by computing them independently,
but leaving the Reduce phase up to the consumer.
The data processing should have a very limited bandwidth usage and reasonable
CPU usage. However, we also need the CPU usage not to be affected by the number
of clients using the processed data. This is where the previous attempt using
MapReduce showed its limits. Of course, horizontal scalability has to be
ensured, to be able to scale with the Riak cluster.
One way of achieving this is to perform the data processing continuously for
every datum that reach Riak, upfront. That way, client requests are actually
only querying the results of the processing, and not triggering computation at
query time.
No back-processing
The data processing will have to be performed on real-time data, but no
back-processing will be done. When a data processing implementation changes, it
will be effective on future events only. If old data is changed or added
(usually as a result of reprocessing), data processing will be applied,
but using the latest version of processing jobs. We don’t want to maintain any
history of data processing, nor any migration of processed data.
To avoid putting too much pressure on the Riak cluster, we only allow data
transformation that produces a small result (to limit storage and bandwidth
footprint), and that runs quickly, with a strong timeout on execution time.
Back-pressure management is very important, and we have a specific strategy to
handle it (see “Back-pressure management strategy” below)
The solution: Substreams
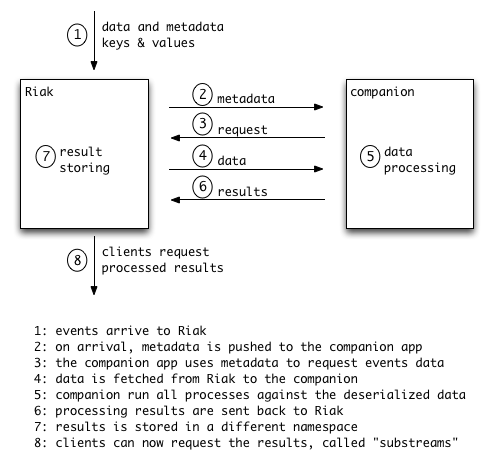
With these features and compromises listed, it is now possible to describe the
data processing layer that we ended up implementing at Booking.com.
This system is called Substreams. Every seconds, the list of keys of the
data that has just been stored is sent to a companion app - a home-made daemon -
running on every Riak node. This fetches the data, decompresses it, runs a
list of data transformation code on it, and stores the results back into Riak,
using the same key name but with a different namespace. Users can now fetch the
processed data.
A data transformation code is called a substream because most of the time the
data transformation is more about cherry-picking exactly the needed fields and
values out of the full stream, rather than performing complex operations.
The companion app is actually a simple pre-forking daemon with a Rest API. It’s
installed on all nodes of the cluster, with around 10 forks. The Rest API is
used to send it the list of keys, and wait for the process completion. The
events data doesn’t transit via this API; the daemon is fetching itself the key
values from Riak, and stores the substreams (results of data transformation)
back into Riak.
The main purpose of this system is to drastically reduce the size of data
transferred to the end user by enabling the cherry-picking of specific branches
or leaves of the events structures, and also to perform preliminary data
processing on the events. Usually, clients are fetching these substreams to
perform more complex and broader aggregations and computations (for instance
as a data source for Machine Learning).
Unlike MapReduce, this system has multiple benefits:
Data decompressed only once
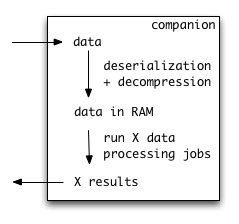
A given binary blob of events (at mot 500K of compressed data) is handled by
one instance of the companion app, which will decompress it once, then run all
the data processing jobs on the decompressed data structure in RAM. This is a
big improvement compared to MapReduce, the most CPU intensive task is
actually to decompress and deserialise the data, not to transform it. Here
we have the guarantee that data is decompressed only once in its lifetime.
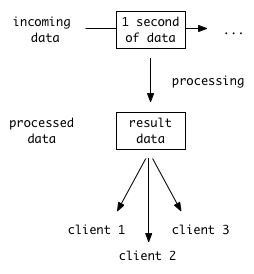
Unlike MapReduce, once a transformation code is setup and enabled, it’ll be
computed for every epoch, even if nobody uses the result. However, the
computation will happen only once, even if multiple users request it later
on. Data transformation is already done when users want to fetch the result.
That way, the cluster is protected against simultaneous requests of a big
number of users. It’s also easier to predict the performance of the substreams
creations.
Data decompression and transformation by the companion app is performed under a
global timeout that would kill the processing if it takes too long. It’s easy
to come up with a realistic timeout value given the average size of event
blobs, the number of companion instances, and the total number of nodes. The
hard timeout makes sure that data processing is not using too many resources,
ensuring that Riak KV works smoothly.
This mechanism allows the cluster to be an open platform: any developer in the
company can create a new substream transformation and quickly get it up and
running on the cluster on its own without asking for permission. There is no
critical risk for the business as substreams runs are capped by a global
timeout. This approach is a good illustration of the flexible and agile
spirit in IT that we have at Booking.com.
Implementation using a Riak commit hook
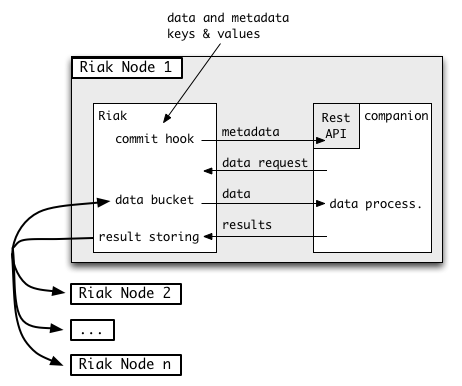
In this diagram we can see where the Riak commit hook kicks in. We can also see
that when the companion requests data from the Riak service, there is a high
chance that the data is not on the current node and Riak has to get it from
other nodes. This is done transparently by Riak, but it consumes bandwidth. In
the next section we’ll see how to reduce this bandwidth usage and have full
data locality. But for now, let’s focus on the commit hook.
Commit hooks are
a feature of Riak that allow the Riak cluster to execute a provided callback
just before or just after a value is written, using respectively pre-commit and
post-commit hooks. The commit hook is executed on the node that coordinated the
write.
We set up a post-commit hook on the metadata bucket (the epochs bucket). We
implemented the commit hook callback, which is executed each time a key is
stored to that metadata bucket. In
part 2 of this series, we explained
that the metadata is stored in the following way:
- the key is
<epoch>-<datacenter_id>, for example: 1413813813-1
- the value is the list of data keys (for instance
1413813813:2:type3::0)
The post-commit hook callback is quite simple: for each metadata key, it gets
the value (the list of data keys), and sends it over HTTP in async
mode to the companion app. Proper timeouts are set so that the execution of
the callback is capped and can’t impact the Riak cluster performance.
Hook implementation
First, let’s write the post commit hook code:
:::erlang
metadata_stored_hook(RiakObject) ->
Key = riak_object:key(RiakObject),
Bucket = riak_object:bucket(RiakObject),
[ Epoch, DC ] = binary:split(Key, <<"-">>),
MetaData = riak_object:get_value(RiakObject),
DataKeys = binary:split(MetaData, <<"|">>, [ global ]),
send_to_REST(Epoch, Hostname, DataKeys),
ok.
send_to_REST(Epoch, Hostname, DataKeys) ->
Method = post,
URL = "http://" ++ binary_to_list(Hostname)
++ ":5000?epoch=" ++ binary_to_list(Epoch),
HTTPOptions = [ { timeout, 4000 } ],
Options = [ { body_format, string },
{ sync, false },
{ receiver, fun(ReplyInfo) -> ok end }
],
Body = iolist_to_binary(mochijson2:encode( DataKeys )),
httpc:request(Method,
{URL, [], "application/json", Body},
HTTPOptions, Options),
ok.
These two Erlang functions (here they are simplified and would probably not
compile), are the main part of the hook. The function metadata_stored_hook is
going to be the entry point of the commit hook, when a metadata key is
stored. It receives the key and value that was stored, via the RiakObject,
uses its value to extract the list of data keys. This list is then sent to the
companion damone over Http using send_to_REST.
The second step is to get the code compiled and Riak setup to be able to use it
is properly. This is described in the documentation about
custom code.
Enabling the Hook
Finally, the commit hook has to be added to a Riak bucket-type:
riak-admin bucket-type create metadata_with_post_commit \
'{"props":{"postcommit":["metadata_stored_hook"]}'
Then the type is activated:
riak-admin bucket-type activate metadata_with_post_commit
Now, anything sent to Riak to be stored with a key within a bucket whose
bucket-type is metadata_with_post_commit will trigger our callback
metadata_stored_hook.
The hook is executed on the coordinator node, that is, the node that received
the write request from the client. It’s not necessary the node where this
metadata will be stored.
The companion app
The companion app is a Rest service, running on all Riak nodes, listening on
port 5000, ready to receive a json blob, which is the list of data keys that
Riak has just stored. The daemon will fetch these keys from Riak, decompress
their values, deserialise them and run the data transformation code on them.
The results are then stored back to Riak.
There is little point showing the code of this piece of software here, as it’s
trivial to write. We implemented it in Perl using
a PSGI preforking web server
(Starman). Using a Perl based web server
allowed us to also have the data transformation code in Perl, making
it easy for anyone in the IT department to write some of their own.
Optimising intra-cluster network usage
As seen saw earlier, if the commit hook simply sends the request to the local
companion app on the same Riak node, additional bandwidth usage is consumed to
fetch data from other Riak nodes. As the full stream of events is quite big
(around 150 MB per second), this bandwidth usage is significant.
In an effort to optimise the network usage, we have changed the post-commit
hook callback to group the keys by the node that is responsible for their
values. The keys are then sent to the companion apps running on the associated
nodes. That way, a companion app will always receive event keys for which data
are on the node they are running on. Hence, fetching events value will not use
any network bandwidth. We have effectively implemented 100% data locality
when computing substreams.
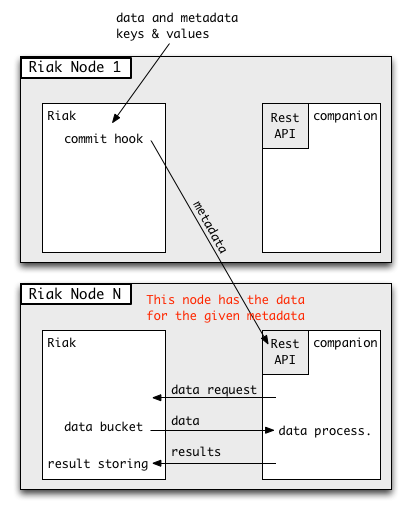
This optimisation is implemented by using Riak’s internal API that gives the list
of primary nodes responsible for storing the value of a given key. More
precisely, Riak’s Core application API provides the preflist() function: (see
the API here) that is
used to map the result of the hashed key to its primary nodes.
The result is a dramatic reduction of network usage. Data processing is
optimised by taking place on one of the nodes that store the given data. Only
the metadata (very small footprint) and the results (a tiny fraction
of the data) travel on the wire. Network usage is greatly reduced.
Back-pressure management strategy
For a fun and easy-to-read description of what back-pressure is and how to
react to it, you can read this great post by Fred Hebert (@mononcqc):
Queues Don’t Fix Overload.
What if there are too many substreams, or one substream is buggy and performs
very costly computations (especially as we allow developers to easily write
their own substream), or all of a sudden the events fullstream change, one
type becomes huge and a previously working substream now takes 10 times
more to compute?
One way of dealing with that is to allow back-pressure: the substream creation
system will inform the stream storage (Riak) that it cannot keep up, and that
it should reduce the pace at which it stores events. This is however not
practical here. Doing back-pressure that way will lead to the storage slowing
down, and transmitting the back-pressure upward the pipeline.
However, events can’t be “slowed down”. Applications send events at a given pace
and if the pipeline can’t keep up, events are simply lost. So propagating
back-pressure upstream will actually lead to load-shedding of events.
The other typical alternative is applied here: doing load-shedding straight
away. If a substream computation is too costly in CPU time, wallclock time,
disk IO or space, the data processing is simply aborted. This protects the Riak
cluster from slowing down events storage - which after all, is its main and
critical job.
That leaves the substream consumers downstream with missing data. Substreams
creation is not guaranteed anymore. However, we used a trick to mitigate the
issue. We implemented a dedicated feature in the common consumer library code;
when a substream is unavailable, the full stream is fetched instead, and the
data transformation is performed on the client side.
It effectively pushes the overloading issue down to the consumer, who can
react appropriately, depending on the guarantees they have to fulfill, and
their properties.
- Some consumers are part of a cluster of hosts that are capable of sustaining
the added bandwidth and CPU usage for some time.
- Some other systems are fine with delivering their results later on, so the consumers will simply be very slow and lag behind real-time.
- Finally, some less critical consumers will be rendered useless because they
cannot catch up with real-time.
However, this multitude of ways of dealing with the absence of
substreams, concentrated at the end of the pipeline, is a very safe yet
flexible approach. In practice, it is not so rare that a substream result for
one epoch is missing (one blob every couple of days), and such blips have no
incidence on the consumers, allowing for a very conservative behaviour of the Riak
cluster regarding substreams: “when in doubt, stop processing substreams”.
Conclusion
This data processing mechanism proved to be very reliable and well-suited for
our needs. The implementation required surprisingly small amount of
code, leveraging features of Riak that proved to be flexible and easy to use.
Notes
[1] It is not strictly true that our events are schema-less. They obey the
structure that the producers found the most useful and natural. But they are so
many producers which each of them sending events that have a different schema,
so it’s almost equivalent to considering them schema-less. Our events can be
seen as structured, yet with so many schemas that they can’t be traced. There
is also complete technical freedom to change the structure of an event, if it’s
seen as useful by a producer.
[2] After spending some time looking at and decoding Sereal blobs, the
human eye easily recognizes common data structures like small HashMaps, small
Arrays, small Integers and VarInts, and of course, Strings, since their content
is untouched. That makes Sereal an almost human readable serialisation format,
especially after a hexdump.
[3] This can be worked around by using secondary indexes (2i) if the
backend is eleveldb or Riak Search, to create additional indexes on keys, thus
enabling listing them in various ways.
[4] Some optimisation has been done, the main action was to implement a
module to split a sereal blob without deserialising it, thus speeding up the
process greatly. This module can be found here:
Sereal::Splitter. Most of the time
spent in splitting sereal blobs is now spent in decompressing it. The next
optimization step would be to use compression that decrunches faster than the
currently used gzip; for instance LZ4_HC.
[5] At that point, the attentive reader may jump in the air and proclaim
“LevelDB and snappy compression!”. It is indeed possible to use LevelDB as Riak
storage backend, which provides an option to use Snappy compression on the
blocks of data stored. However, this compression algorithm is not good enough
for our need (using gzip reduced the size by a factor of almost 2). Also,
Leveldb (or at least the eleveldb implementation that is used in Riak) doesn’t
provide automatic expiration which is critical to us, and had issues with
reclaiming free space after key deletions, with versions below 2.x
[6] Using MapReduce on Riak is usually somewhat discouraged because most of the
time it’s being used in a wrong way, for instance when performing bulk fetch or bulk
insert or traversing a bucket. The MapReduce implementation in Riak is very
powerful and efficient, but must be used properly. It works best when
used on a small number of keys, even if the size of data processed is very
large. The fewer keys the less bookkeeping and the better performance. In our
case, there are only a couple of hundred keys for one second worth of data (but
somewhat large values, around 400K), which is not a lot. Hence the great
performance of MapReduce we’ve witnessed. YMMV.